- Published on
RAG - Encoder and Reranker evaluation
Summary
One of the key components in building a RAG (Retrieval-Augmented Generation) system is the evaluation part. In this blog post, let us see how we can evaluate the performance of the encoder and the reranker components of the RAG system. We will explore how we can use a custom testing dataset for evaluation, using LlamaIndex.
RAG system
Retrieval Augmented Generation, aka RAG systems, combines the power of LLMs with external data sources without costly pre-training/fine-tuning. Building a RAG system involves several components like query rewriter, encoder, retriever, reranker, generator, etc. If you are interested in knowing more about building an enterprise-grade RAG system, please check out this wonderful blog post by Pratik.
RAG evaluation
Like any other ML system, evaluation plays a crucial role in choosing the right models for the RAG system.
In this blog post, we will specifically focus on evaluating the encoder and the reranker components of the RAG system. We will use LlamaIndex python package for our evaluation. There is already a great blog post on this topic by Ravi Theja. Kindly note that a lot of codes for this blog post is referenced from Ravi's post.
In this blog post, we will use a custom dataset to do our evaluation rather than using the generate_question_context_pairs function to create the question-answer pairs for testing. Also, we will use only the open-source models available.
Code used for this blog post is present in this ipython notebook.
Encoder and Reranker
The Encoder component of the RAG system encodes the corpus/documents into vectors for retrieval. There are a variety of embedding models available for this encoding task, such as Sentence Transformers, JinaAI, OpenAI, etc.
The Reranker component comes after we retrieve the top 'k' documents from our vector store. The reranker then re-ranks these top-k documents to bring the highly relevant documents to the top. Some of the notable reranker models are BGE, Cohere, etc.
Evaluation Metric
Similar to Ravi Theja's blog post, we will use Hit Rate and Mean Reciprocal Rank (MRR) as our evaluation metrics for the retrieval system.
Hit Rate is the fraction of queries for which the correct answer is present in the top-k retrievals. For a given query, if we have a top 'k' value of 5, and if the correct answer is present in the first 5 retrieved documents, then the hit rate will be 1; otherwise, it will be 0.
Mean Reciprocal Rank (MRR) is based on the rank of the highest-placed relevant document. For a given query, we will get the rank of the relevant document and then compute the inverse of the rank to get the query score. For example, if the relevant document is ranked 1, then the score for the given query is 1; if the relevant document is ranked 2, then the score is 0.5 (1/2).
Setting up the environment
We will need the following packages and so let us install them.
llama-index
sentence-transformers
cohere
protobuf
pypdf
datasets
Dataset
We will use the sciq dataset from HuggingFace. This dataset has 13,679 crowdsourced science exam questions and has 6 columns: question, correct answer, 3 wrong answers, support text for correct answer.
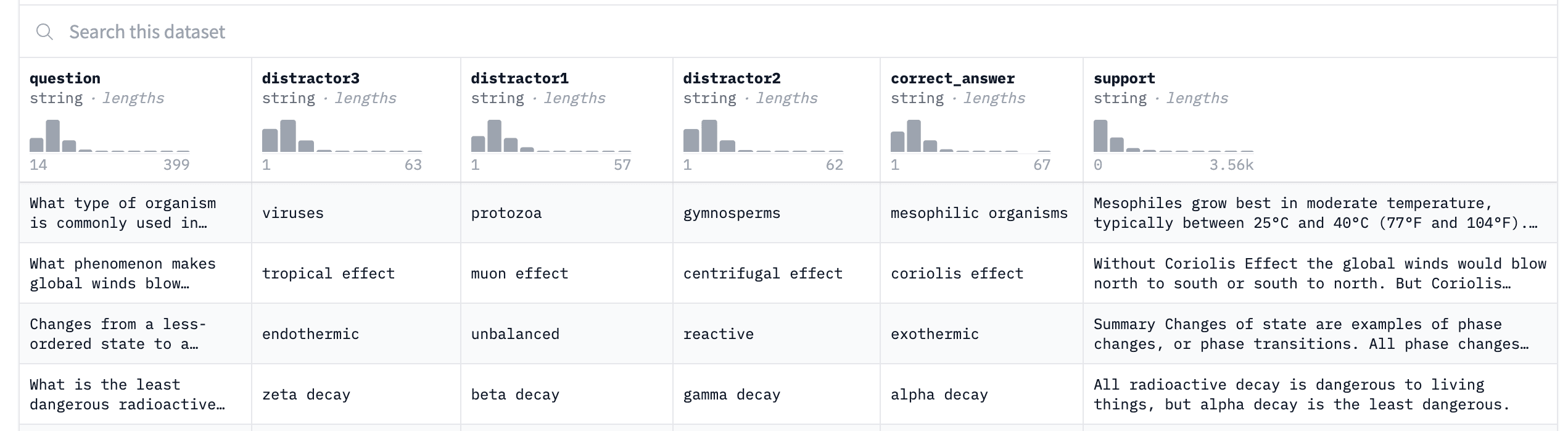
This support text will be our documents to search in RAG for the given question.
Evaluation
Let us start with importing all the necessary modules
from llama_index import VectorStoreIndex, SimpleDirectoryReader, ServiceContext
from llama_index.node_parser import SimpleNodeParser
from llama_index.schema import Document
# LLM
from llama_index.llms import Anthropic
# Embeddings
from llama_index.embeddings import OpenAIEmbedding, HuggingFaceEmbedding, CohereEmbedding
# Retrievers
from llama_index.retrievers import (
BaseRetriever,
VectorIndexRetriever,
)
# Rerankers
from llama_index.indices.query.schema import QueryBundle, QueryType
from llama_index.schema import NodeWithScore
# from llama_index.indices.postprocessor.cohere_rerank import CohereRerank
from llama_index.indices.postprocessor import SentenceTransformerRerank
from llama_index.finetuning.embeddings.common import EmbeddingQAFinetuneDataset
# Evaluator
from llama_index.evaluation import (
generate_question_context_pairs,
EmbeddingQAFinetuneDataset,
)
from llama_index.evaluation import RetrieverEvaluator
from typing import List
import pandas as pd
import nest_asyncio
nest_asyncio.apply()
Now let us laod the dataset.
from datasets import load_dataset
dataset = load_dataset("sciq")
The dataset has more than 13K rows, and just for simplicity, let us take only 500 rows from them for our evaluation. Please feel free to use all the data for your evaluation. We will also take only those documents whose chunk size is less than 512 for ease of use. However, this can be adapted for bigger documents too.
# Set the chunk size as 512 in node parser
node_parser = SimpleNodeParser.from_defaults(chunk_size=512)
corpus = []
filtered_queries = []
counter = 0
for train_row in dataset["train"]:
# Remove the empty documents
if len(train_row["support"].strip()) == 0:
continue
current_document = Document(text=train_row["support"])
# If the number of nodes for the document is 1, use them for evaluation
if len(node_parser.get_nodes_from_documents([current_document])) == 1:
corpus.append(train_row["support"])
filtered_queries.append(train_row["question"])
counter += 1
# Limit to 500 documents
if counter == 500:
break
Now let us create the nodes from the documents. In LlamaIndex, a Node represents a 'chunk' of a source Document. Similar to Documents, they contain metadata and relationship information with other nodes. So, if we have a larger document, we will have multiple nodes for that document.
# Create the nodes from documents
documents = [Document(text=c) for c in corpus]
nodes = node_parser.get_nodes_from_documents(documents)
# Manually assign node id for retrieval and evaluation
for idx, node in enumerate(nodes):
node.id_ = f"corpus_{idx}"
We will use EmbeddingQAFinetuneDataset from LlamaIndex for our evaluation. EmbeddingQAFinetuneDataset needs queries dictionary, corpus dictionary, and the relevant mapping dictionary as inputs. So, let us create them.
# Create inputs for EmbeddingQAFinetuneDataset
queries_dict = {f"query_{index}":filtered_queries[index] for index in range(counter)}
corpus_dict = {f"corpus_{index}":corpus[index] for index in range(counter)}
relevant_docs_dict = {f"query_{index}":[f"corpus_{index}"] for index in range(counter)}
# Create QA dataset
qa_dataset = EmbeddingQAFinetuneDataset(
queries=queries_dict,
corpus=corpus_dict,
relevant_docs=relevant_docs_dict
)
Now, let us define the embeddings and rerankers that we are going to evaluate.
# Define all embeddings and rerankers
EMBEDDINGS = {
"bge-large": HuggingFaceEmbedding(model_name='BAAI/bge-large-en'), # You can use mean pooling by addin pooling='mean' parameter
"JinaAI-Small": HuggingFaceEmbedding(model_name='jinaai/jina-embeddings-v2-small-en', pooling='mean', trust_remote_code=True),
"JinaAI-Base": HuggingFaceEmbedding(model_name='jinaai/jina-embeddings-v2-base-en', pooling='mean', trust_remote_code=True),
}
RERANKERS = {
"WithoutReranker": "None",
"bge-reranker-base": SentenceTransformerRerank(model="BAAI/bge-reranker-base", top_n=5),
"bge-reranker-large": SentenceTransformerRerank(model="BAAI/bge-reranker-large", top_n=5)
}
Please note that we are only using open-source embeddings and rerankers in this blog. Feel free to test it out with other open-source models or closed-source ones.
Now, the first part is the retrieval of the relevant documents using the vector embeddings.
ServiceContext helps us define the LLM and the embedding model. VectorStoreIndex accepts a list of Node objects and creates an index from them using the embedding model. VectorIndexRetriever helps us retrieve the top-k documents from the vector index.
service_context = ServiceContext.from_defaults(llm=None, embed_model=embed_model)
vector_index = VectorStoreIndex(nodes, service_context=service_context)
vector_retriever = VectorIndexRetriever(index=vector_index, similarity_top_k=5, service_context=service_context)
Now, in addition to vector retrieval, we also need to perform reranking. For this purpose, we will use a CustomRetriever class.
# Define Retriever
class CustomRetriever(BaseRetriever):
"""Custom retriever that performs both Vector search and Reranking"""
def __init__(
self,
vector_retriever: VectorIndexRetriever,
) -> None:
"""Init params."""
self._vector_retriever = vector_retriever
def _retrieve(self, query_bundle: QueryBundle) -> List[NodeWithScore]:
"""Retrieve nodes given query."""
retrieved_nodes = self._vector_retriever.retrieve(query_bundle)
if reranker != 'None':
retrieved_nodes = reranker.postprocess_nodes(retrieved_nodes, query_bundle)
else:
retrieved_nodes = retrieved_nodes[:5]
return retrieved_nodes
async def _aretrieve(self, query_bundle: QueryBundle) -> List[NodeWithScore]:
"""Asynchronously retrieve nodes given query.
Implemented by the user.
"""
return self._retrieve(query_bundle)
async def aretrieve(self, str_or_query_bundle: QueryType) -> List[NodeWithScore]:
if isinstance(str_or_query_bundle, str):
str_or_query_bundle = QueryBundle(str_or_query_bundle)
return await self._aretrieve(str_or_query_bundle)
custom_retriever = CustomRetriever(vector_retriever)
Now that we have defined the custom retriever, let us compute the evaluation metrics for our dataset.
retriever_evaluator = RetrieverEvaluator.from_metric_names(
["mrr", "hit_rate"], retriever=custom_retriever
)
eval_results = await retriever_evaluator.aevaluate_dataset(qa_dataset)
Results
Now, let us check the results for our dataset.

- As we can see,
JinaAI-baseembedding model withbge-reranker-largeyielded the best result for this dataset. - Additionally, the Reranker appears to improve the performance for all the embedding models, aligning with the findings of most other people.
Please note that these results are based on this specific dataset and may not hold true for other datasets. Therefore, make sure to run the experiment on your dataset to determine the most suitable Encoder and Reranker for your specific use case.